Convolution Neural Network
Convolution Neural Network(CNN)與其他Deep Model最大的不同是他的架構。以AlexNet為例,CNN則具有兩個不同的部分,左半邊是Feature extracting,最後再將抽取的Feature交給簡單的兩層Full Connected Neural Network進行分類。

Fig. 1 Alex Net
Feature Extraction
在特徵抽取的部分,主要會有幾種不同的動作一種是Convolution,另一種是Max Pooling,這篇主要是講解Convoltion的部分, Max pooling請參考下一篇。 以AlexNet為例,如下圖所示,L1到L2會做幾個動作,第一個動作是一個Convolution的動作,
Step1 Convolution
L1 是一個224X224的圖片也是整個Network的Input,共有三個通道,所以Input大小為224X224X3,L1到L2的動作就是對L1做多種Kernel的Convolution的結果。基本的圖像Convolution的動作可以參考Andrew Ng. UFDL的文件。
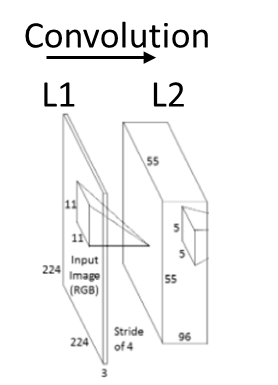
Fig. 2 Convolution from input image to next layer in AlexNet [1]
簡單來說,一個圖像的Convlution需要幾個基本參數,
- Convolution Kernel,以Fig. 2 為例,是使用96個大小為11X11X3的Convolution Kernel。
- 步伐(Stride),由Andrew Ng.的文件中可以知道,圖像的Convolution是透過Kernel對圖像進行Sliding window進行的,這裡的步伐就是只Sliding window 的步伐,以Fig. 2 為例,步伐為4。
有了以上兩個參數我們就可以開始進行Convolution。一個11X11X3的kernel對 2242243的圖像進行Convolution可以得到55X55X1的圖像。
如果親手進行推導的話應該是會得到53X53X1的圖像,那為什麼下一層會是55X55呢? 原因是為了讓224X224的每個區塊的資訊都保留,通常會做一個Padding的動作,將2242243能夠整除,所以會將它變成227X227X3,用227X227X3下去推倒就會得到55X55的答案。
統理可證,我們對Input使用96個11X11X3就會得到55X55X96的輸出。所以基本上L1和L2的關係圖應該表示成Fig. 3 會比較清楚

Fig. 3
Step 2 Rectified Linear Unit
接下來L1到L2的第二個動作是將Convolution後的結果丟入Acitivation Function,在AlxNet中選擇的是rectified linear unit (ReLU)。
在NN的領域裡,Acitivation Function有幾個可能的選擇,根據AlexNet原文,Alex做了一些比較選擇了rectified linear unit的原因有
1.在梯度下降的訓練中,飽和非線性函數比不飽和非線性函數(ReLU)要慢得多,下圖是Alex原文的實驗圖,ReLUs的深度卷積神經網絡比帶tanh單元的同等網絡要快好幾倍。
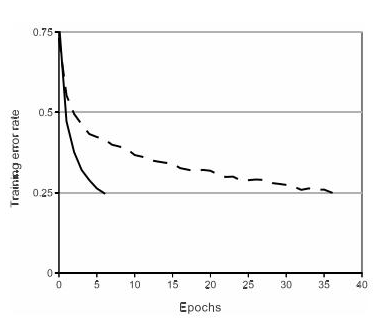
Fig. 4[2]
2.使用飽和非線性函數比不飽和非線性函數的效果沒有什麼差異,甚至更好。
加入ReLU後的Fig.3的結構變成,因為ReLU是對輸入的每一個Pixel做運算,所以經過ReLU之後dimension不會有變化,只有執會改變。

Fig. 5
經由這兩個步驟就完成了第一個Convolution layer的工作,之後的每一個Convolution layer就是以同一個概念進行,不同的是Kernel還有Input。
一般這樣的運作會表示成下列的數學公式,
Convolution step:
其中l代表第幾層,i代表輸入圖像的上的座標(一般圖像處理會將輸入圖表示成一維矩陣), 代表第j 個convolution kernel,是第層第j個kernel的bias。
ReLU step:
Convlution 層之後一般就會接到Pooling層,Pooling 層的解釋請參照Pooling的解釋。
Reference:
[1]http://blog.sina.com.cn/s/blog_eb3aea990102v47i.html
[2]Krizhevsky, A., et al. (2012). Imagenet classification with deep convolutional neural networks. Advances in neural information processing systems.